
Сайт открывается медленно, запросы висят по 5-10 секунд, SSH подключается с задержкой. Причина может быть в CPU, памяти, диске или сети - и каждый случай лечится по-своему. Статья показывает, как за 10-15 минут найти узкое место с помощью стандартных инструментов.
Первый осмотр: load average
Первое, что смотрим при подозрении на тормоза - load average. Он показывает среднее число процессов, ожидающих выполнения, за последние 1, 5 и 15 минут:
uptime
# или
cat /proc/loadavg
Вывод: 10:23:41 up 12 days, load average: 3.21, 2.87, 1.94
Три числа - среднее за 1 минуту, 5 минут и 15 минут.
Нормальное значение load average зависит от числа CPU-ядер. На 2-ядерном VPS load average 2.0 - это полная загрузка. Load average 4.0 на том же сервере означает, что 2 процесса постоянно ждут ресурсов.
nproc # узнать число ядер
Правило: если load average за 1 минуту больше числа ядер в 2 раза и при этом значение не снижается (сравни с 15-минутным) - это проблема, а не пик.
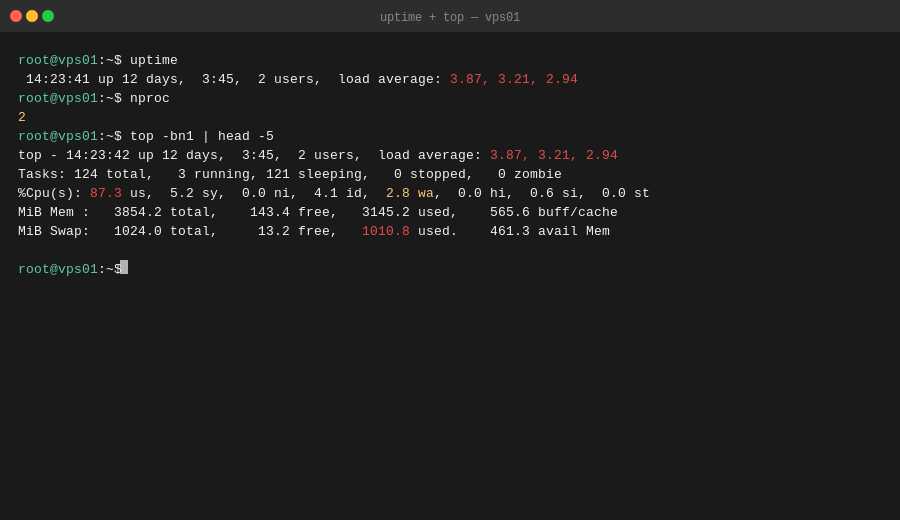
Шаг 1. CPU - top и htop
Открываем top:
top
Первые строки после заголовка - состояние CPU:
%Cpu(s): 87.3 us, 5.2 sy, 0.0 ni, 4.1 id, 2.8 wa, 0.0 hi, 0.6 si
Ключевые колонки:
us(user) - CPU занят пользовательскими процессамиsy(system) - CPU в ядре ОСid(idle) - свободенwa(iowait) - CPU ждёт ввода-вывода с диска
Если us + sy близко к 100% и id около 0 - CPU перегружен.
Если wa высокий (выше 20-30%) - проблема не в CPU, а в диске.
В top нажимаем P для сортировки по CPU, смотрим топ-3 процесса. Это виновник.
htop даёт более наглядную картину с цветовой индикацией по ядрам:
sudo apt install -y htop
htop
В htop F6 открывает сортировку, F9 - kill-сигнал выбранному процессу.
Шаг 2. Память - free и vmstat
free -h
Вывод:
total used free shared buff/cache available
Mem: 3.8Gi 3.1Gi 142Mi 212Mi 589Mi 461Mi
Swap: 1.0Gi 987Mi 13Mi
Смотри на available, а не на free. available - реальная память, доступная для новых процессов, с учётом освобождаемого кэша.
В примере выше: 461 МБ available, Swap используется на 987 МБ из 1 ГБ. Это критическое состояние - сервер активно использует swap, производительность упала в 10-100 раз по сравнению с оперативной памятью.
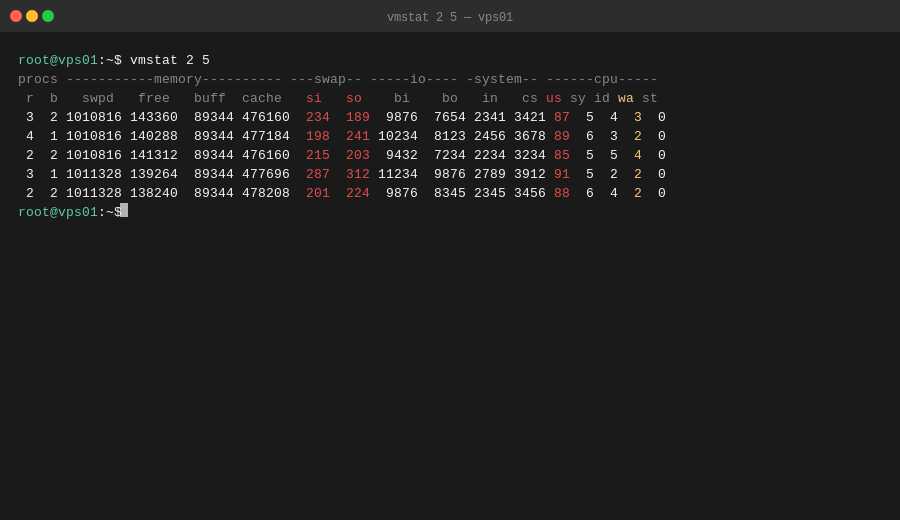
Динамику использования памяти показывает vmstat:
vmstat 2 10
10 замеров с интервалом 2 секунды. Смотри на колонки:
si(swap in) - страницы читаются из swap в RAMso(swap out) - страницы вытесняются из RAM в swap
Если si и so ненулевые постоянно - память заканчивается и система активно свапирует.
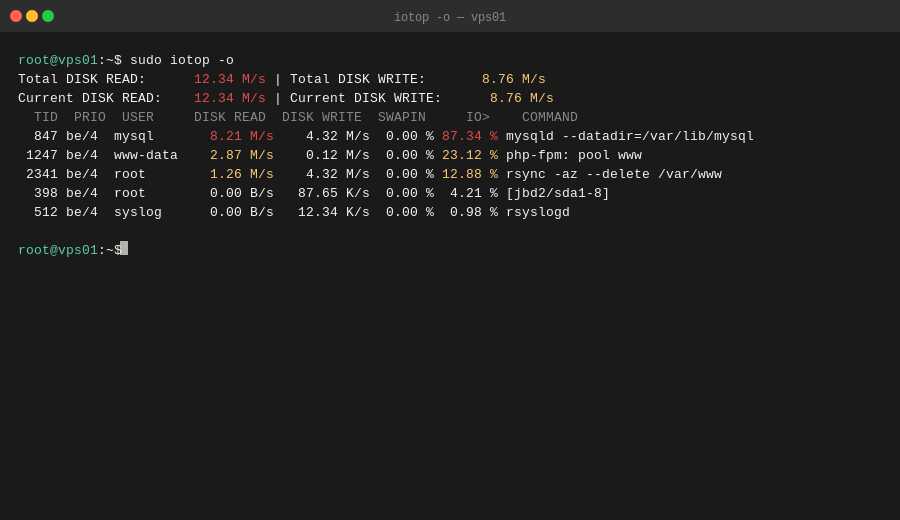
Шаг 3. Диск - iotop и iostat
Высокий wa в top указывает на I/O bottleneck. Смотрим, кто именно грузит диск:
sudo apt install -y iotop
sudo iotop -o
Флаг -o показывает только процессы с ненулевой I/O активностью. Типичные виновники: MySQL без query cache при полных table scan, PHP-FPM пишущий логи на каждый запрос, backup-процесс запустился в неудобное время.
Для более детальной статистики по устройствам - iostat:
sudo apt install -y sysstat
iostat -x 2 5
Ключевая метрика - %util. Значение 100% означает, что диск занят постоянно. На SSD это может быть нормой при высоком IOPS, но на HDD 100% %util - явное узкое место.
Также смотри на await - среднее время ожидания I/O операции в миллисекундах. На SSD нормально < 1-2 мс, на HDD < 10 мс. Значения 50+ мс означают, что очередь на диск переполнена.
Шаг 4. Типичные виновники
PHP-FPM
PHP-FPM на пике создаёт много worker-процессов, которые держат память. При нехватке памяти они начинают ждать, запросы копятся.
Проверяем статус PHP-FPM:
sudo systemctl status php8.3-fpm
# Смотрим на active workers
sudo php-fpm8.3 -t # проверка конфига
Ключевые параметры в /etc/php/8.3/fpm/pool.d/www.conf:
pm = dynamic
pm.max_children = 20 ; максимум воркеров
pm.start_servers = 5 ; при старте
pm.min_spare_servers = 2 ; минимум простаивающих
pm.max_spare_servers = 10 ; максимум простаивающих
pm.max_requests = 500 ; рестарт воркера после N запросов (защита от утечек памяти)
Для подбора pm.max_children: дели доступную RAM на средний размер одного PHP-процесса. Размер смотри через ps aux | grep php-fpm | awk '{print $6}' | sort -n.
MySQL
Медленные запросы без индексов - частая причина высокого I/O и CPU на MySQL серверах.
Включаем slow query log:
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 1;
SET GLOBAL slow_query_log_file = '/var/log/mysql/slow.log';
Через 10-15 минут анализируем:
sudo mysqldumpslow -s t -t 10 /var/log/mysql/slow.log
Покажет топ-10 самых медленных запросов по суммарному времени. Для каждого запускай EXPLAIN в mysql-клиенте - видно, использует ли он индексы.
Java (Tomcat, Spring Boot)
Java-приложения часто «тормозят» из-за GC pause - сборщик мусора останавливает все потоки. Симптом: кратковременные зависания на 1-3 секунды.
Смотрим GC логи:
# Для JVM 17+ запусти приложение с флагами:
-Xlog:gc*:file=/var/log/app/gc.log:time,uptime:filecount=5,filesize=20m
grep "GC" /var/log/app/gc.log | tail -20
Частые GC с длительностью больше 500 мс - сигнал увеличить heap (-Xmx) или пересмотреть GC-стратегию.
Шаг 5. Сеть
Если top и iotop ничего подозрительного не показывают, а тормоза есть - смотрим на сеть.
# Трафик по интерфейсам в реальном времени
sudo apt install -y nload
nload eth0
Или nethogs для разбивки по процессам:
sudo apt install -y nethogs
sudo nethogs eth0
Проверяем потери пакетов:
ping -c 100 8.8.8.8 | tail -3
Потери пакетов больше 1% влияют на производительность TCP - браузеры делают retry, задержки накапливаются.
Шаг 6. Быстрый чеклист диагностики
uptime- load average выше числа ядер?free -h- available < 200 МБ или swap > 50%?top-wa> 20%? Какой процесс занимает CPU?sudo iotop -o- кто грузит диск?vmstat 2 5- ненулевыеsi/so?Логи виновника-процесса:
journalctl -u nginx -n 50,/var/log/mysql/slow.log
Обычно тормоза укладываются в один из трёх сценариев: заканчивается память и сервер уходит в swap, диск перегружен неоптимальными запросами к БД, или PHP/Java процессы занимают весь CPU из-за неэффективного кода.
Итог
Диагностика производительности VPS - это последовательное сужение подозреваемых: сначала load average и CPU, потом память, потом диск, потом сеть. Инструменты top, htop, free, iotop, iostat и vmstat устанавливаются из пакетов в базовых репозиториях. Всё, что нужно для первичного расследования, есть на любом Linux-сервере без дополнительной установки.