Ollama - это инструмент, который превращает запуск языковых моделей из сложной задачи настройки Python-окружений в выполнение одной команды. Установил, скачал модель, запустил. Всё работает через REST API, который совместим с форматом OpenAI. Рассмотрим установку на Linux с GPU и без, конкретные модели, требования к железу и как подключить Ollama к своему приложению.
Требования к серверу
Модели работают на CPU, GPU или обоих. Скорость генерации кардинально отличается:
Конфигурация | Модель | Скорость генерации |
|---|---|---|
CPU: 8 ядер, 32 GB RAM | Llama 3.2 3B | 5–10 токенов/сек |
CPU: 16 ядер, 64 GB RAM | Llama 3.3 70B (Q4) | 1–3 токена/сек |
GPU: NVIDIA RTX 3090 (24 GB VRAM) | Llama 3.3 70B (Q4) | 30–50 токенов/сек |
GPU: NVIDIA A100 40 GB | Llama 3.3 70B (FP16) | 80–120 токенов/сек |
Для комфортной работы на CPU нужны модели до 8B параметров. Модели 13B–70B на CPU работают медленно и годятся для пакетной обработки, но не для диалога в реальном времени.
Минимальные требования для CPU-инференса:
4 vCPU
16 GB RAM (для моделей до 8B)
30 GB свободного дискового пространства
Для GPU-инференса дополнительно:
NVIDIA GPU с поддержкой CUDA 12.x
Драйверы NVIDIA 525.x и выше
nvidia-container-toolkit (если используете Docker)
Установка Ollama на Linux
Стандартная установка (рекомендуется)
curl -fsSL https://ollama.com/install.sh | sh
Скрипт:
Скачивает бинарный файл Ollama (~100 MB)
Создаёт системного пользователя
ollamaРегистрирует systemd-сервис
ollamaОпределяет наличие GPU и настраивает CUDA-поддержку
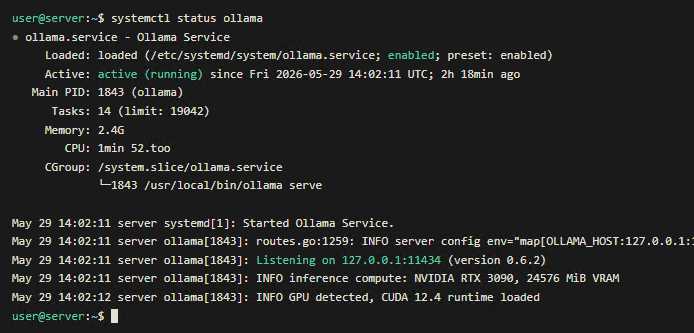
systemctl status ollama
Ollama слушает на 127.0.0.1:11434 по умолчанию.
Ручная установка (для кастомных конфигураций)
Скачайте бинарник напрямую:
curl -L https://ollama.com/download/ollama-linux-amd64 -o /usr/local/bin/ollama
chmod +x /usr/local/bin/ollama
Создайте пользователя и директории:
useradd -r -s /bin/false -m -d /usr/share/ollama ollama
mkdir -p /usr/share/ollama/.ollama
chown -R ollama:ollama /usr/share/ollama
Создайте systemd-юнит /etc/systemd/system/ollama.service:
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
# Директория для хранения моделей
Environment="OLLAMA_MODELS=/usr/share/ollama/.ollama/models"
# Разрешить подключения с любого IP (если нужен внешний доступ)
# Environment="OLLAMA_HOST=0.0.0.0:11434"
[Install]
WantedBy=default.target
systemctl daemon-reload
systemctl enable --now ollamaУстановка с поддержкой NVIDIA GPU
Перед установкой Ollama убедитесь, что драйверы установлены:
nvidia-smi
Вывод покажет версию драйвера и доступные GPU. Если nvidia-smi не найден:
# Ubuntu 22.04 / 24.04
apt install -y nvidia-driver-535
reboot
После перезагрузки снова запустите nvidia-smi. Если всё в порядке, установите Ollama стандартным скриптом - он автоматически обнаружит GPU.
Проверка, что Ollama использует GPU:
ollama run llama3.2:3b "Hello"
В другом терминале:
nvidia-smi
В столбце GPU-Util должна быть ненулевая нагрузка.
Загрузка и запуск моделей
Основные команды
# Загрузить модель
ollama pull llama3.3:70b-instruct-q4_K_M
# Запустить интерактивный чат
ollama run mistral:7b
# Запустить конкретный вариант
ollama run gemma3:27b-it-q4_K_M
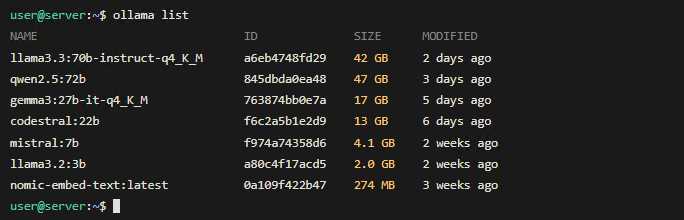
# Список загруженных моделей
ollama list
# Удалить модель
ollama rm llama3.2:1bПопулярные модели и их размеры
Llama 3.3 70B (Meta, 2024)
Квантованный Q4_K_M: ~43 GB
Требует 48+ GB RAM или VRAM
Команда:
ollama pull llama3.3:70b-instruct-q4_K_M
Llama 3.2 3B (Meta, 2024)
Размер: ~2 GB
Требует 8 GB RAM
Команда:
ollama pull llama3.2:3bХорошо работает на CPU, быстрая генерация
Mistral 7B v0.3 (Mistral AI)
Размер Q4: ~4.1 GB
Требует 8 GB RAM
Команда:
ollama pull mistral:7bХороший баланс качества и скорости
Gemma 3 27B (Google, 2025)
Квантованный Q4: ~17 GB
Команда:
ollama pull gemma3:27b-it-q4_K_M
Qwen2.5 72B (Alibaba)
Квантованный Q4: ~47 GB
Команда:
ollama pull qwen2.5:72bЛучший вариант для задач с кодом
Codestral 22B (Mistral AI - специализирован для кода)
Квантованный Q4: ~13 GB
Команда:
ollama pull codestral:22b
Кастомные модели через Modelfile
Modelfile позволяет настроить поведение модели: системный промпт, температуру, контекст.
cat > Modelfile << 'EOF'
FROM llama3.2:3b
SYSTEM """
Ты технический ассистент. Отвечай только на вопросы о Linux, Docker и DevOps.
Давай краткие конкретные ответы с примерами команд.
"""
PARAMETER temperature 0.3
PARAMETER num_ctx 4096
PARAMETER top_p 0.9
EOF
ollama create devops-assistant -f Modelfile
ollama run devops-assistantREST API
Ollama предоставляет HTTP API, совместимый с форматом OpenAI.
Генерация текста (не streaming)
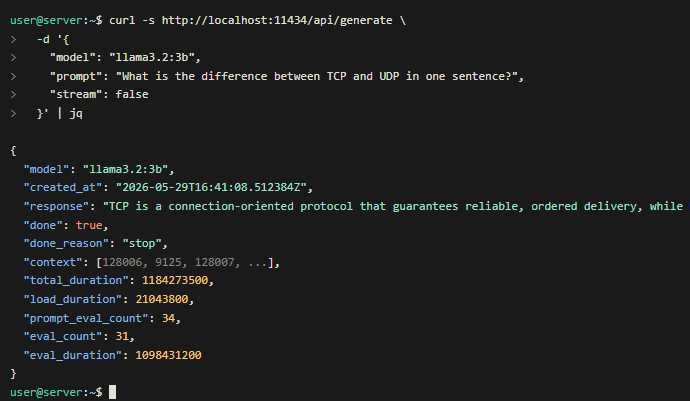
curl -s http://localhost:11434/api/generate \
-d '{
"model": "llama3.2:3b",
"prompt": "Объясни разницу между TCP и UDP в двух предложениях",
"stream": false
}' | jq '.response'Генерация в режиме streaming
curl -s http://localhost:11434/api/generate \
-d '{
"model": "llama3.2:3b",
"prompt": "Напиши bash-скрипт для бэкапа директории",
"stream": true
}'
Каждая строка ответа - отдельный JSON-объект с полем response.
Чат (messages API - совместим с OpenAI)
curl -s http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral:7b",
"messages": [
{"role": "system", "content": "Ты опытный DevOps-инженер."},
{"role": "user", "content": "Как проверить открытые порты на Linux?"}
]
}' | jq '.choices[0].message.content'
Эндпоинт /v1/chat/completions принимает запросы в формате OpenAI API. Любая библиотека, написанная для OpenAI, будет работать с Ollama без изменений кода - только поменяйте base URL.
Список доступных моделей (OpenAI-совместимый)
curl http://localhost:11434/v1/models | jq '.data[].id'Embeddings
curl http://localhost:11434/api/embeddings \
-d '{
"model": "nomic-embed-text",
"prompt": "Текст для создания эмбеддинга"
}'Использование из Python
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama", # любая строка, API-ключ не нужен
)
response = client.chat.completions.create(
model="llama3.2:3b",
messages=[
{"role": "user", "content": "Напиши функцию на Python для парсинга JSON"}
],
temperature=0.3,
max_tokens=1024,
)
print(response.choices[0].message.content)Доступ извне и безопасность
По умолчанию Ollama принимает только локальные подключения. Чтобы открыть API на внешний мир:
В /etc/systemd/system/ollama.service добавьте:
Environment="OLLAMA_HOST=0.0.0.0:11434"
systemctl daemon-reload && systemctl restart ollama
Внимание: открытый без аутентификации Ollama API позволяет любому скачивать модели, запускать генерацию и нагружать ваш сервер. Защитите его одним из способов:
Nginx с Basic Auth перед
11434VPN (WireGuard/Tailscale) и доступ только из VPN-подсети
Firewall:
ufw allow from 10.0.0.0/8 to any port 11434
Оптимизация производительности
Количество потоков CPU:
Environment="OLLAMA_NUM_THREADS=8"
Размер контекста: большой контекст требует больше RAM. По умолчанию 2048 токенов. Для больших документов увеличьте:
ollama run llama3.2:3b --ctx-size 8192
Кэширование модели в памяти: Ollama держит последнюю использованную модель в памяти. Если запустить две разные модели подряд - первая выгрузится. Для фиксации модели в RAM:
ollama run llama3.2:3b "" # загружает модель и держит в памяти
Количество слоёв на GPU: если VRAM не хватает для всей модели, Ollama автоматически часть слоёв размещает на CPU. Полный GPU-инференс быстрее, чем гибридный.
Итог
Ollama 0.6.x (актуальная версия на начало 2026) превращает запуск LLM в рутинную операцию. Для CPU-сервера с 16 GB RAM выбирайте модели до 8B параметров: Llama 3.2 3B или Mistral 7B. Для GPU-серверов с 24 GB VRAM подходят 70B-модели в Q4-квантовании. REST API совместим с форматом OpenAI, поэтому интеграция с существующим кодом минимальна. Для продакшена закройте порт 11434 через firewall.