Зачем читать это, если есть top?
top и htop удобны для «поглядеть», но не всегда удобны для скриптов, отчётов и точных срезов. Корректнее и стабильнее формировать выдачу через ps, а для временных рядов — через pidstat из пакета sysstat. Так вы избегаете хрупкого парсинга и получаете предсказуемые колонки и сортировку.
Как правильно показать «топ-10 по CPU»
Вариант 1 — ps (рекомендовано для скриптов)
# Топ-10 процессов по среднему %CPU на момент опроса
ps -eo pid,ppid,user,comm,%cpu --sort=-%cpu | head -n 11
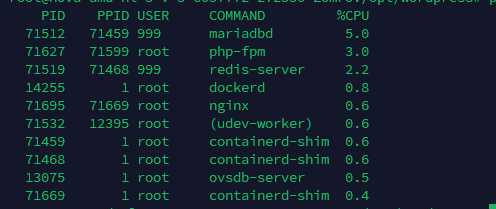
Почему так:
--sort=-%cpu— официально поддерживаемая сортировка в procpsps.Фиксируем набор колонок, чтобы не ломать парсер, если локаль/ширина терминала изменится.
Полезные вариации:
# Показать «скользящее» время жизни (ETIMES) и командную строку покороче
ps -eo pid,etimes,user,args:60,%cpu --sort=-%cpu | head -n 11
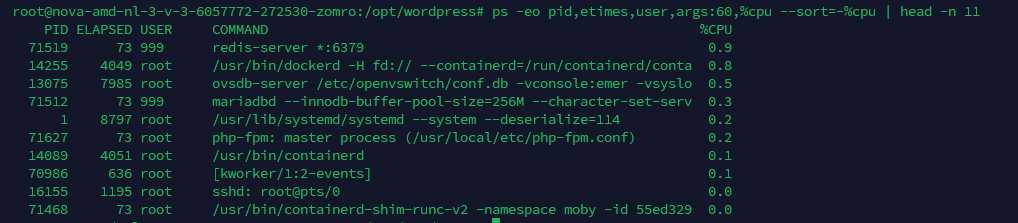
# Увидеть «горячие» потоки (TID) внутри процесса
ps -eLo pid,tid,psr,comm,%cpu --sort=-%cpu | head -n 15
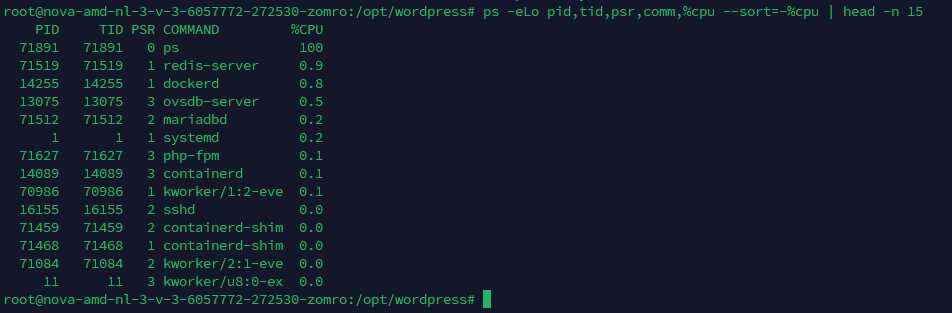
Примечание: %CPU у ps/top — это доля CPU, усреднённая между обновлениями; на многопроцессорных системах значение может превышать 100% для многопоточных задач (сумма по ядрам).
Вариант 2 — top (интерактивно)
Запустите
top, нажмите Shift+O (или Shift+F) → выберите поле %CPU → Enter.Для сохранения вида в
htop: P (или F6 → CPU% → F10).
Как смотреть динамику (не один снимок, а «кто жрёт сейчас»)
pidstat (лучше для временных рядов)
# Обновление каждую 1 секунду, 5 итераций, все PID
pidstat -u -p ALL 1 5
Плюс pidstat в том, что он показывает дельту нагрузки за интервал, а не мгновенный снимок. Это честнее для пульсирующих нагрузок (воркеры, сборщики).
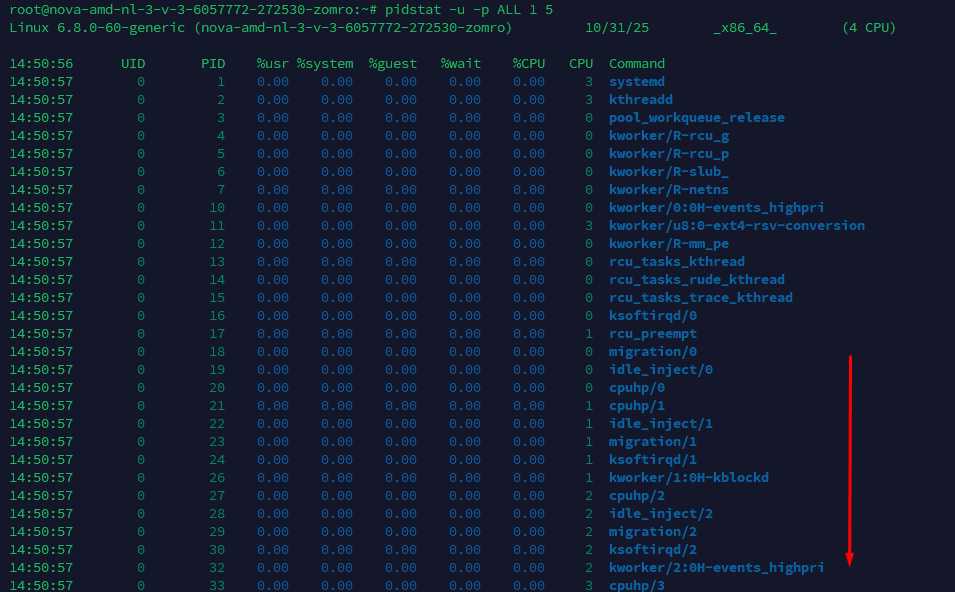
Сводка по конкретному процессу:
pidstat -u -p <PID> 1 10
Частые ошибки и как их избежать
Парсинг
top -b. В batch-режимеtopменяет формат при разных версиях/локалях/ширине окна — хрупко. Для автосборов используйтеps/pidstat.Путаем «время CPU» и «реальное время». Поля
TIME+вtop— накопленное CPU-время, а не wall-clock. Это нормально, просто учитывайте смысл метрики.Не видим «горячие» потоки. Смотрите
ps -eLo ...— так поймаете runaway‑поток в Java/NGINX/PHP‑FPM.Не фиксируем поля. В
psвсегда указывайте колонки явно (-eo ...) и сортировку (--sort), иначе получите неожиданные столбцы.
Мини-шпаргалка задач
Задача A: «Дайте топ-10 по CPU прямо сейчас»
ps -eo pid,ppid,user,comm,%cpu --sort=-%cpu | head -n 11
Задача B: «Кто именно внутри процесса грузит ядро»
ps -eLo pid,tid,psr,comm,%cpu --sort=-%cpu | head -n 20
Задача C: «Нужно мониторить 5 минут и вывести среднюю картину»
# pidstat делает 60 срезов раз в 5 секунд (≈5 минут)
pidstat -u -p ALL 5 60 | tee pidstat.log
Задача D: «Быстрый интерактивный взгляд»
top→ отсортируйте по %CPU;htop→ P (CPU) или F6 → CPU% → F10 для сохранения.
Автоматизация (cron / systemd-timer)
Запись «топ-10» в лог каждые 5 минут:
*/5 * * * * ps -eo pid,comm,%cpu --sort=-%cpu | head -n 11 >> /var/log/cpu_top.log
Когда «топ-10 по CPU» — не то, что вам нужно
Проблема не в CPU, а в steal/iowait — CPU «свободен», но приложение «медленное». В таких кейсах смотрите ещё
mpstat,iostat, профайлеры, метрики гипервизора/облака. (Здесь мы фокусируемся именно на CPU‑«пожирателях».)
Краткое резюме
Точечный срез →
ps --sort=-%cpuс явными колонками.Динамика за интервал →
pidstat -u(sysstat).Интерактивно →
top/htopс сортировкой по CPU.Для потоков и «виновников» внутри PID →
ps -eLo ....